Java JDOM2 – XML 读取示例
原文: https://howtodoinjava.com/xml/jdom2-read-parse-xml-examples/
JDOM 解析器可用于在更新 XML 内容后用于读取 XML,解析 XML 和写入 XML 文件。 它将 JDOM2 文档存储在内存中,以读取和修改其值。
将 XML 文档加载到内存中后,JDOM2 维护严格的父子类型关系。 父类型的 JDOM 实例(父)具有访问其内容的方法,子类型的 JDOM 实例(内容)具有访问其父对象的方法。
Table of Contents
Project Structure
JDOM2 Maven Dependency
Create JDOM2 Document
Read and filter XML content
Read XML Content with XPath
Complete Example
源码下载
项目结构
请创建此文件夹结构以执行示例。 这是在 Eclipse 中创建的简单 Maven 项目。
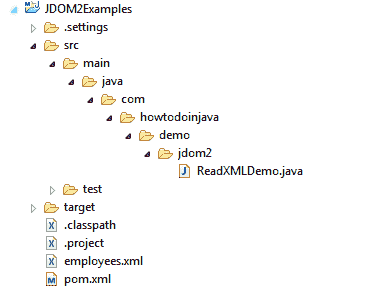
项目结构
请注意,我已经使用了 lambda 表达式和方法引用,因此您需要配置为使用 JDK 1.8。
JDOM2 Maven 依赖关系
<dependency>
<groupId>org.jdom</groupId>
<artifactId>jdom2</artifactId>
<version>2.0.6</version>
</dependency>
要执行 XPath,您还需要 jaxen。
<dependency>
<groupId>jaxen</groupId>
<artifactId>jaxen</artifactId>
<version>1.1.6</version>
</dependency>
创建 JDOM2 文档
您可以使用下面列出的任何解析器创建org.jdom2.Document实例。 它们都解析 XML 并返回内存中的 JDOM 文档。
-
使用 DOM 解析器
private static Document getDOMParsedDocument(final String fileName) { Document document = null; try { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //If want to make namespace aware. //factory.setNamespaceAware(true); DocumentBuilder documentBuilder = factory.newDocumentBuilder(); org.w3c.dom.Document w3cDocument = documentBuilder.parse(fileName); document = new DOMBuilder().build(w3cDocument); } catch (IOException | SAXException | ParserConfigurationException e) { e.printStackTrace(); } return document; } -
使用 SAX 解析器
private static Document getSAXParsedDocument(final String fileName) { SAXBuilder builder = new SAXBuilder(); Document document = null; try { document = builder.build(fileName); } catch (JDOMException | IOException e) { e.printStackTrace(); } return document; } -
使用 StAX 解析器
private static Document getStAXParsedDocument(final String fileName) { Document document = null; try { XMLInputFactory factory = XMLInputFactory.newFactory(); XMLEventReader reader = factory.createXMLEventReader(new FileReader(fileName)); StAXEventBuilder builder = new StAXEventBuilder(); document = builder.build(reader); } catch (JDOMException | IOException | XMLStreamException e) { e.printStackTrace(); } return document; }
读取和过滤 XML 内容
我将读取employees.xml文件。
<employees>
<employee id="101">
<firstName>Lokesh</firstName>
<lastName>Gupta</lastName>
<country>India</country>
<department id="25">
<name>ITS</name>
</department>
</employee>
<employee id="102">
<firstName>Brian</firstName>
<lastName>Schultz</lastName>
<country>USA</country>
<department id="26">
<name>DEV</name>
</department>
</employee>
</employees>
读取根节点
使用document.getRootElement()方法。
public static void main(String[] args)
{
String xmlFile = "employees.xml";
Document document = getSAXParsedDocument(xmlFile);
Element rootNode = document.getRootElement();
System.out.println("Root Element :: " + rootNode.getName());
}
输出:
Root Element :: employees
读取属性值
使用Element.getAttributeValue()方法。
public static void main(String[] args)
{
String xmlFile = "employees.xml";
Document document = getSAXParsedDocument(xmlFile);
Element rootNode = document.getRootElement();
rootNode.getChildren("employee").forEach( ReadXMLDemo::readEmployeeNode );
}
private static void readEmployeeNode(Element employeeNode)
{
//Employee Id
System.out.println("Id : " + employeeNode.getAttributeValue("id"));
}
输出:
Id : 101
Id : 102
读取元素值
使用Element.getChildText()或Element.getText()方法。
public static void main(String[] args)
{
String xmlFile = "employees.xml";
Document document = getSAXParsedDocument(xmlFile);
Element rootNode = document.getRootElement();
rootNode.getChildren("employee").forEach( ReadXMLDemo::readEmployeeNode );
}
private static void readEmployeeNode(Element employeeNode)
{
//Employee Id
System.out.println("Id : " + employeeNode.getAttributeValue("id"));
//First Name
System.out.println("FirstName : " + employeeNode.getChildText("firstName"));
//Last Name
System.out.println("LastName : " + employeeNode.getChildText("lastName"));
//Country
System.out.println("country : " + employeeNode.getChild("country").getText());
/**Read Department Content*/
employeeNode.getChildren("department").forEach( ReadXMLDemo::readDepartmentNode );
}
private static void readDepartmentNode(Element deptNode)
{
//Department Id
System.out.println("Department Id : " + deptNode.getAttributeValue("id"));
//Department Name
System.out.println("Department Name : " + deptNode.getChildText("name"));
}
Output:
FirstName : Lokesh
LastName : Gupta
country : India
Department Id : 25
Department Name : ITS
FirstName : Brian
LastName : Schultz
country : USA
Department Id : 26
Department Name : DEV
使用 XPath 读取 XML 内容
要使用 xpath 读取任何元素的值集,您需要编译XPathExpression并使用其evaluate()方法。
String xmlFile = "employees.xml";
Document document = getSAXParsedDocument(xmlFile);
XPathFactory xpfac = XPathFactory.instance();
//Read employee ids
XPathExpression<Attribute> xPathA = xpfac.compile("//employees/employee/@id", Filters.attribute());
for (Attribute att : xPathA.evaluate(document))
{
System.out.println("Employee Ids :: " + att.getValue());
}
//Read employee first names
XPathExpression<Element> xPathN = xpfac.compile("//employees/employee/firstName", Filters.element());
for (Element element : xPathN.evaluate(document))
{
System.out.println("Employee First Name :: " + element.getValue());
}
输出:
Employee Ids :: 101
Employee Ids :: 102
Employee First Name :: Lokesh
Employee First Name :: Brian
完整的 JDOM2 XML 读取示例
这是在 Java 中使用 JDOM2 读取 xml 的完整代码。
package com.howtodoinjava.demo.jdom2;
import java.io.FileReader;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamException;
import org.jdom2.Attribute;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.filter.Filters;
import org.jdom2.input.DOMBuilder;
import org.jdom2.input.SAXBuilder;
import org.jdom2.input.StAXEventBuilder;
import org.jdom2.xpath.XPathExpression;
import org.jdom2.xpath.XPathFactory;
import org.xml.sax.SAXException;
@SuppressWarnings("unused")
public class ReadXMLDemo
{
public static void main(String[] args)
{
String xmlFile = "employees.xml";
Document document = getSAXParsedDocument(xmlFile);
/**Read Document Content*/
Element rootNode = document.getRootElement();
System.out.println("Root Element :: " + rootNode.getName());
System.out.println("\n=================================\n");
/**Read Employee Content*/
rootNode.getChildren("employee").forEach( ReadXMLDemo::readEmployeeNode );
System.out.println("\n=================================\n");
readByXPath(document);
}
private static void readEmployeeNode(Element employeeNode)
{
//Employee Id
System.out.println("Id : " + employeeNode.getAttributeValue("id"));
//First Name
System.out.println("FirstName : " + employeeNode.getChildText("firstName"));
//Last Name
System.out.println("LastName : " + employeeNode.getChildText("lastName"));
//Country
System.out.println("country : " + employeeNode.getChild("country").getText());
/**Read Department Content*/
employeeNode.getChildren("department").forEach( ReadXMLDemo::readDepartmentNode );
}
private static void readDepartmentNode(Element deptNode)
{
//Department Id
System.out.println("Department Id : " + deptNode.getAttributeValue("id"));
//Department Name
System.out.println("Department Name : " + deptNode.getChildText("name"));
}
private static void readByXPath(Document document)
{
//Read employee ids
XPathFactory xpfac = XPathFactory.instance();
XPathExpression<Attribute> xPathA = xpfac.compile("//employees/employee/@id", Filters.attribute());
for (Attribute att : xPathA.evaluate(document))
{
System.out.println("Employee Ids :: " + att.getValue());
}
XPathExpression<Element> xPathN = xpfac.compile("//employees/employee/firstName", Filters.element());
for (Element element : xPathN.evaluate(document))
{
System.out.println("Employee First Name :: " + element.getValue());
}
}
private static Document getSAXParsedDocument(final String fileName)
{
SAXBuilder builder = new SAXBuilder();
Document document = null;
try
{
document = builder.build(fileName);
}
catch (JDOMException | IOException e)
{
e.printStackTrace();
}
return document;
}
private static Document getStAXParsedDocument(final String fileName)
{
Document document = null;
try
{
XMLInputFactory factory = XMLInputFactory.newFactory();
XMLEventReader reader = factory.createXMLEventReader(new FileReader(fileName));
StAXEventBuilder builder = new StAXEventBuilder();
document = builder.build(reader);
}
catch (JDOMException | IOException | XMLStreamException e)
{
e.printStackTrace();
}
return document;
}
private static Document getDOMParsedDocument(final String fileName)
{
Document document = null;
try
{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//If want to make namespace aware.
//factory.setNamespaceAware(true);
DocumentBuilder documentBuilder = factory.newDocumentBuilder();
org.w3c.dom.Document w3cDocument = documentBuilder.parse(fileName);
document = new DOMBuilder().build(w3cDocument);
}
catch (IOException | SAXException | ParserConfigurationException e)
{
e.printStackTrace();
}
return document;
}
/*private static String readFileContent(String filePath)
{
StringBuilder contentBuilder = new StringBuilder();
try (Stream<String> stream = Files.lines( Paths.get(filePath), StandardCharsets.UTF_8))
{
stream.forEach(s -> contentBuilder.append(s).append("\n"));
}
catch (IOException e)
{
e.printStackTrace();
}
return contentBuilder.toString();
}*/
}
输出:
Root Element :: employees
=================================
Id : 101
FirstName : Lokesh
LastName : Gupta
country : India
Department Id : 25
Department Name : ITS
Id : 102
FirstName : Brian
LastName : Schultz
country : USA
Department Id : 26
Department Name : DEV
=================================
Employee Ids :: 101
Employee Ids :: 102
Employee First Name :: Lokesh
Employee First Name :: Brian
源代码下载
学习愉快!
参考文献: